My Role
Solo developer, full ownership: product direction, architecture, data pipeline, frontend, backend, infrastructure, and deployment. This is a personal project, not client work. I defined the problem, designed the system, and built every piece of it. It's been in active development for over a year.
I built this because my family went through the search process and I saw how broken it was firsthand. The people using this platform are families in crisis, often an adult child who just learned their parent can't live alone anymore. They're not power users. Every design decision started from that: the information has to be trustworthy, the filters have to surface what actually matters for care, and the UI can't get in the way of someone who's overwhelmed.
Approach
Monorepo with two workspaces (pnpm + Turbo):
- Backend: Express 5 with Zod-validated routes, MongoDB (Mongoose), Redis + Bull job queues, S3 storage, and Socket.io for real-time admin features. 24 database models, 25 route handlers.
- Frontend: React Router 7 with SSR, Tailwind v4, shadcn/ui, Jotai for search state, TanStack React Query, Google Maps integration, TipTap rich text editor, and Recharts for analytics dashboards.
Four user roles: admin, provider (facility operators who claim and manage listings), advertiser (auction-based ad campaigns with geo-targeting), and seeker (families). Each role has its own dashboard, permissions, and workflow. Providers go through a verification flow to claim facilities: domain-based auto-approval, verification codes sent to facility email, or document upload for admin review.
Deployed via Docker on Coolify (self-hosted CI/CD) with Cloudflare for ingress and Traefik reverse proxy. Staging and production environments with environment-aware configuration.
Data Pipeline
The platform lives or dies on data quality. I built a multi-source ingestion pipeline that pulls from six state registries: WA (DSHS), OR (DHS), CA (CDSS), NV (DPBH), MT (DPHHS), ID (IDHW), plus CMS federal nursing home data. Each state publishes in a different format: CSV, HTML tables, PDFs, APIs. Each adapter handles parsing, normalization, and deduplication independently.
Enrichment workers run on Bull job queues and fill in what the registries don't provide:
- Web scraping (Cheerio) facility websites for amenities, photos, and descriptions
- Google Places API for coordinates, ratings, and photos
- LLM-powered field extraction: mapping free-form facility descriptions to structured attributes (care types, security features, room configurations)
- Three caching layers (scrape cache, Google cache, LLM cache) to control API costs and respect rate limits
A deduplication service reconciles overlapping data. The same facility can appear in a state registry, CMS federal data, and a Google Places result. The system merges these into a single canonical listing with source tracking. The pipeline currently maintains ~26,000 listings.
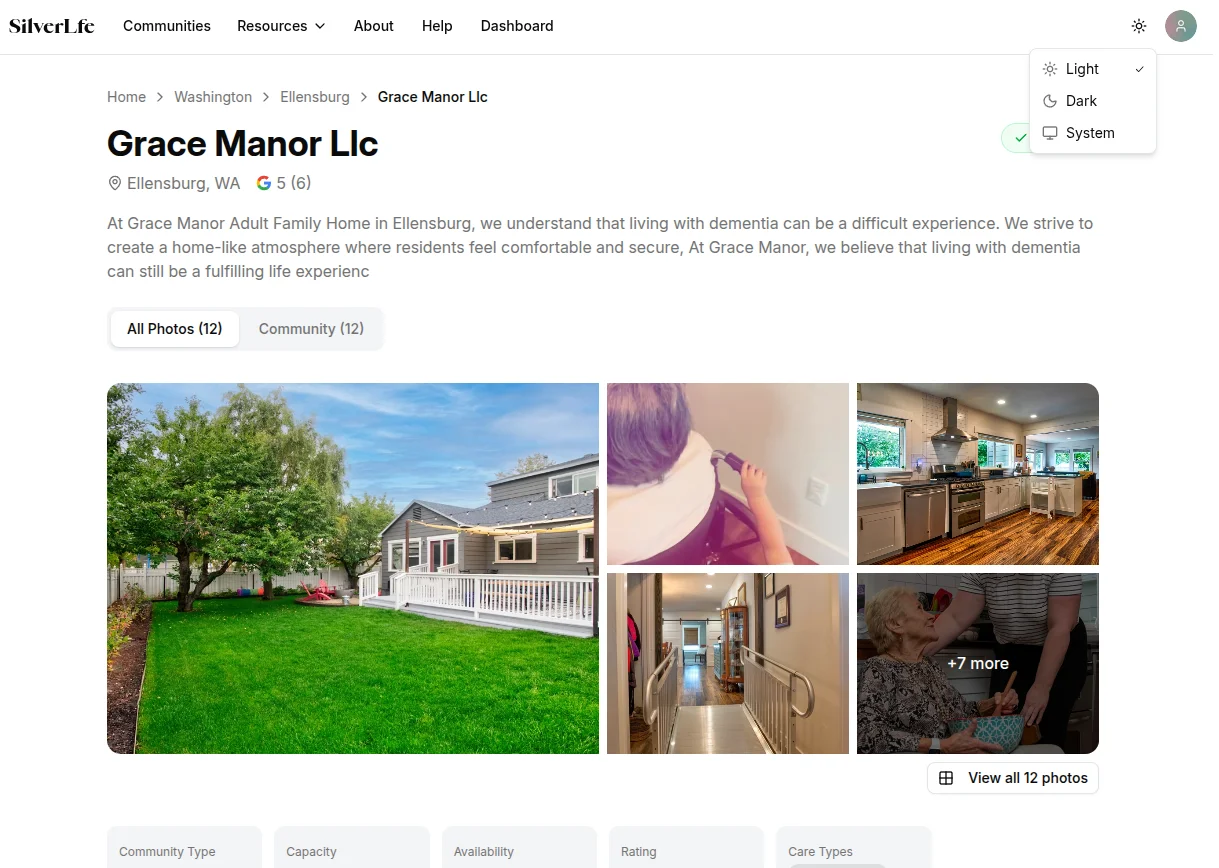
Key Decisions
MongoDB over PostgreSQL. Facility data is deeply nested and varies wildly by source. Rooms have features, staff have specializations, medical capabilities are arrays of enums, security features differ by facility type. A relational schema would mean dozens of join tables for what's naturally a document. MongoDB's document model maps directly to this shape. Geospatial indexing on coordinates handles location queries without PostGIS.
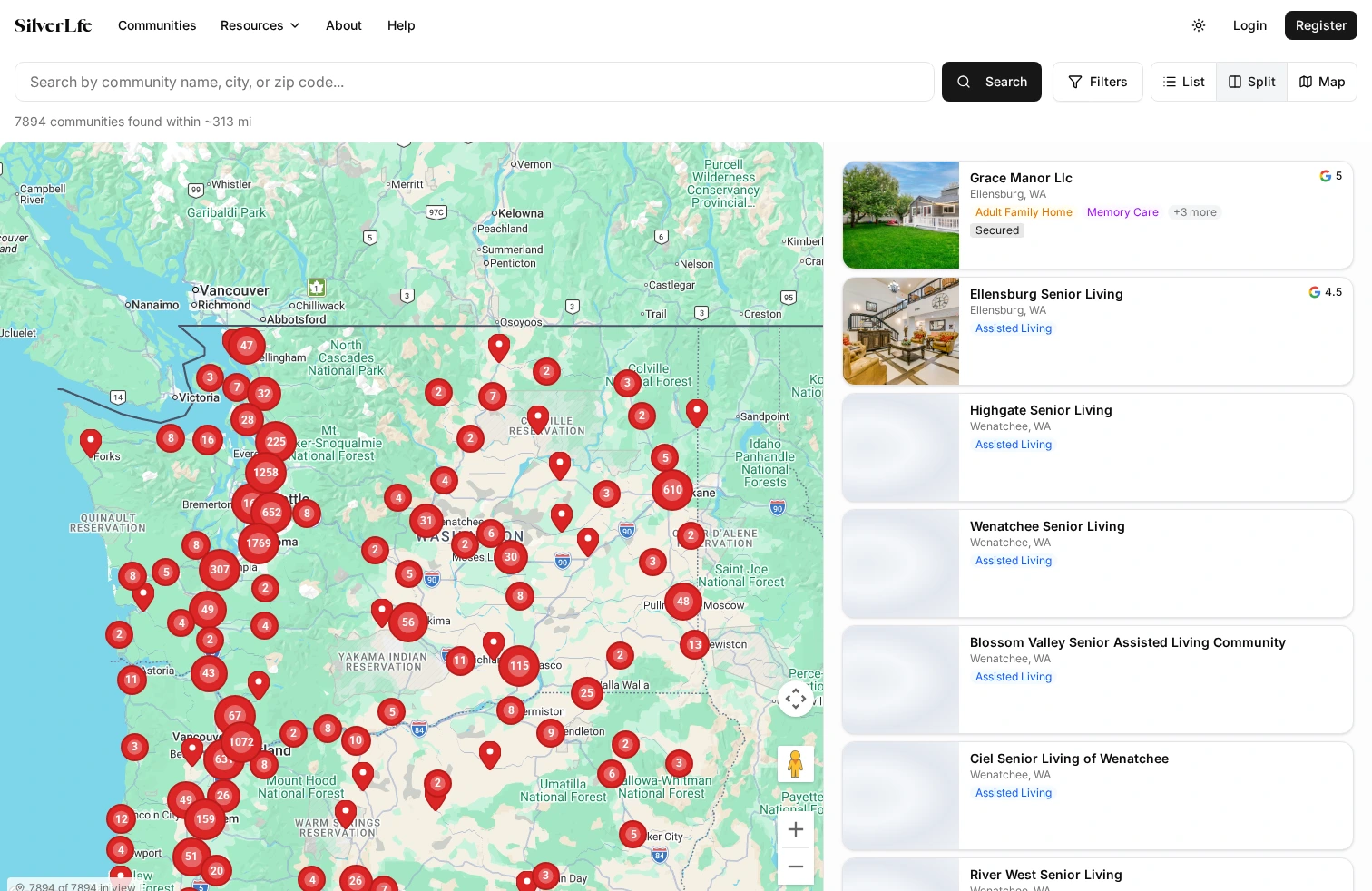
Map viewport drives the query. All three view modes (list, split, map) query the same geographic area using viewport bounds. Panning and zooming the map loads new data for the visible area. This sounds simple but the implementation was not. I had to handle search lifecycle across view-mode switches, progressive expansion ("Show more" widens the query bounds by 10 miles per click), accumulated result deduplication, and debounced map-idle events to prevent query cascades. Search state lives in Jotai atoms so it survives navigation.
Bull job queues for enrichment. Enrichment is slow and failure-prone. Web scraping breaks, APIs rate-limit, LLM inference takes seconds per record. Bull + Redis gives me retry logic with backoff, rate limiting, progress tracking, and the ability to pause and resume enrichment runs without losing state. I can enrich 26,000 listings without babysitting the process.
Zod for runtime validation + OpenAPI generation. Every route validates input with Zod schemas. The same schemas generate OpenAPI documentation automatically via zod-to-openapi. This eliminated an entire class of bugs where the frontend sent data the backend didn't expect.
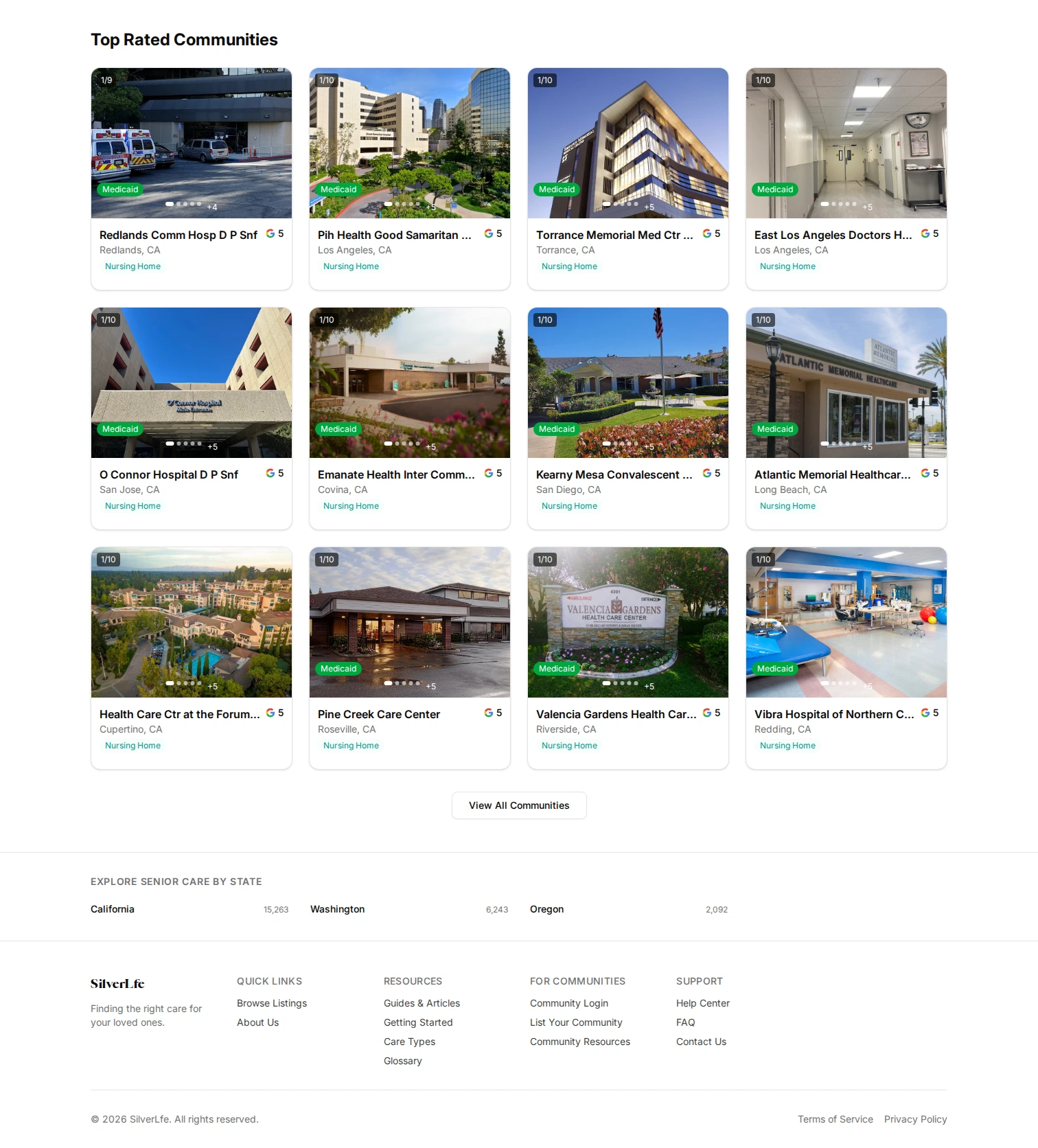
What Was Hard
State registry parsing. Every state publishes facility data differently. Washington gives you a decent CSV. California publishes HTML tables that change format without notice. Some states embed data in PDFs. Each adapter is its own mini-project with its own failure modes. When a state changes their page layout, the scraper breaks silently. I built health checks that flag stale data so I know when an adapter needs attention.
LLM enrichment at scale. Facility websites describe their services in free-form text. "We welcome residents with memory challenges in a secure, homelike setting" needs to map to structured attributes: care_types includes memory_care, security_features includes secured_environment. I use LLM-powered extraction for this, but the output needs validation. The model sometimes hallucinates attributes. Every LLM result passes through a Zod schema before it touches the database. Results are cached so I'm not paying per-record on re-runs.
Search UX across three view modes. List, split-panel, and full-map views all need to show the same data, respond to the same filters, and stay in sync when switching between them. The edge cases were brutal. What happens to expanded results when you switch from list to split? What if the map viewport captures a different area than the expansion bounds? I ended up with a detailed state architecture spec just for search, and rewrote the system twice before it felt right.
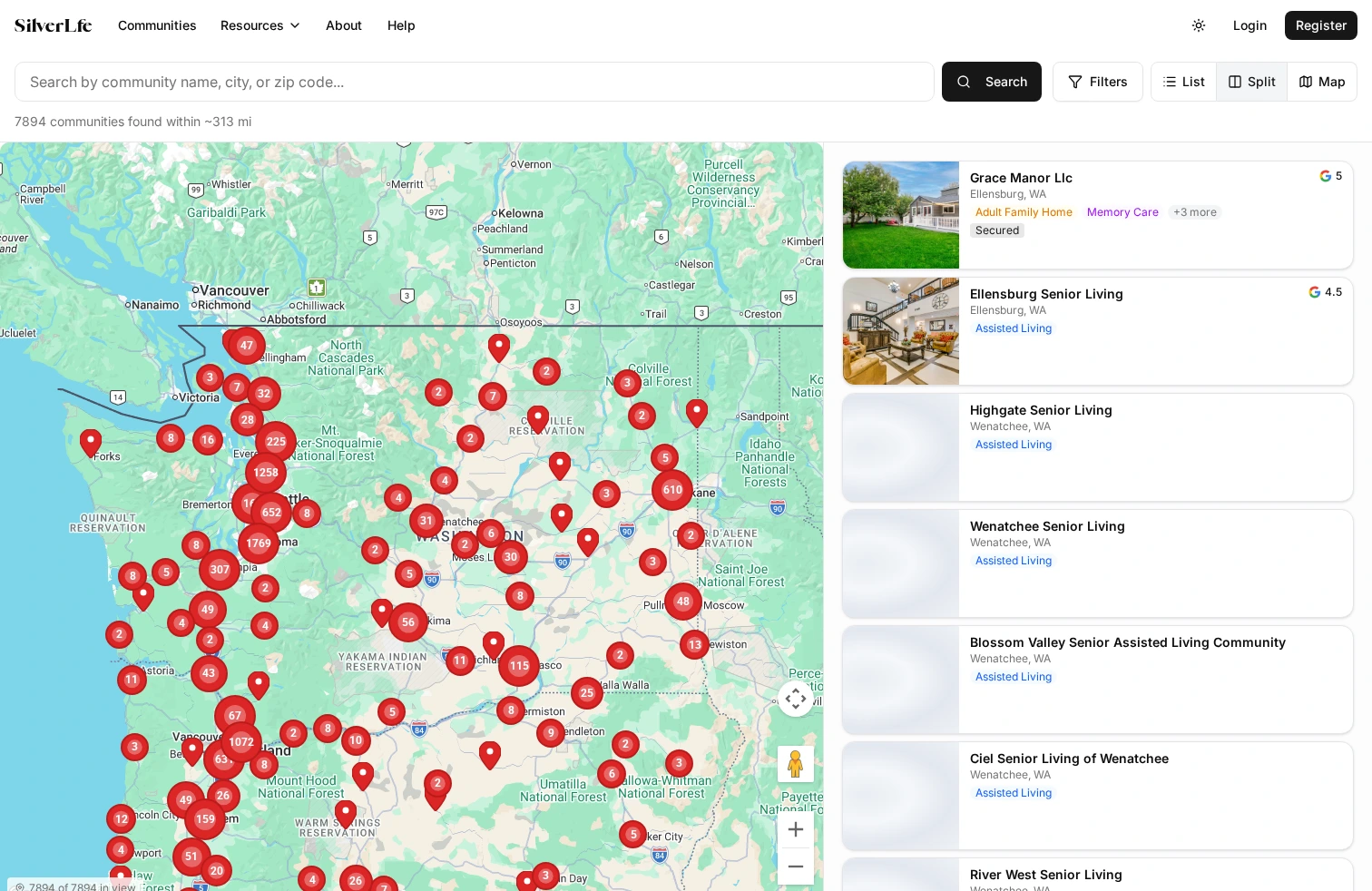
The Result
The platform is deployed to staging with ~26,000 facility listings across six states. 79 filterable dimensions across 10 categories: care type, medical capabilities, security features, staffing ratios, room preferences, end-of-life care, location, price, availability, and lifestyle amenities. Three view modes (list, split, full map) with viewport-driven data loading and progressive radius expansion.
Beyond search, the platform includes a facility comparison tool (side-by-side, up to 3 facilities), loved one profiles (care recipient assessments that can be exported as PDF for facility tours), a provider dashboard with claim verification and profile completion tracking, an advertiser platform with auction-based bidding and geo-targeted campaigns, an inquiry messaging system (threaded, with email notifications), a cost estimator, and an article system with MDX content.
This was a large project that touched data engineering (multi-source pipelines, LLM enrichment, deduplication), full-stack product development (four user roles, real-time features, payment systems), and infrastructure (Docker, Coolify CI/CD, Cloudflare). It's not finished (the backlog has real items from QA walkthroughs and provider onboarding sessions), but the core system works and the data pipeline runs.